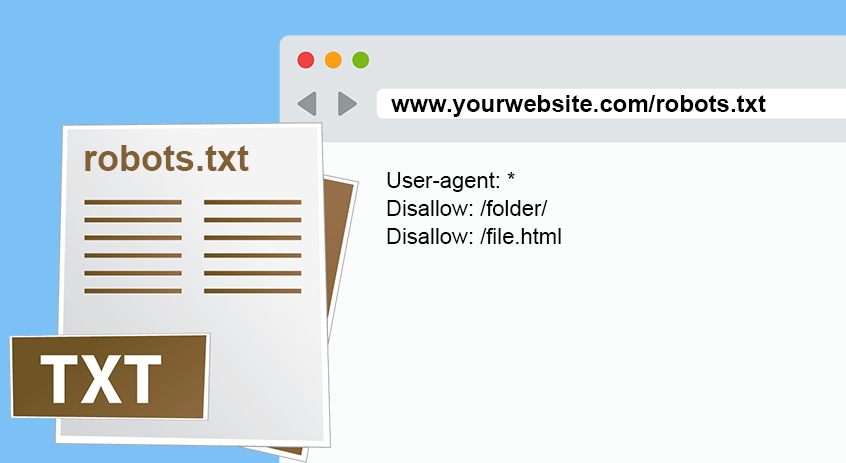
Robots.txt is a simple text file that informs web crawlers (also known as spiders or bots) about which parts of a website or blog to be crawled and which parts should not be crawled.
Why Robots.txt File is Important?
Well, the success of any professional blogs usually depends on how Google search engine ranks your blog. We store a number of posts/pages/files/directories in our website structure. Often we don’t want Google to index all these components. For example, you may have a file for internal use — and it is of no use for the search engines. You don’t want this file to appear in search results. Therefore, it is prudent to hide such files from search engines. Robots.txt file contains directives which all the top search engines honor. Using these directives you can give instructions to web spiders to ignore certain portions of your website/blog.
Custom Robots.txt for Blogger/Blogspot
Because Blogger/Blogspot is a free blogging service, robots.txt of your blog was not directly in your control. But now Blogger has made it possible to make changes and create a Custom Robots.txt for each blog. Robots.txt for a Blogger/Blogspot blog looks typically like this:
Add Custom Robots.txt File on Blogger/Blogspot
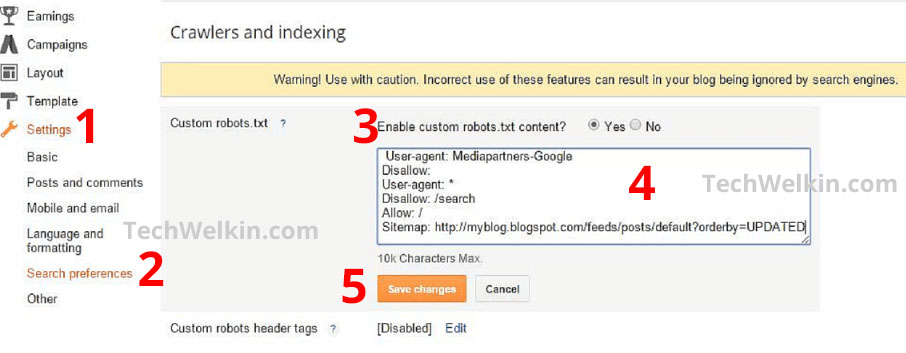
Go to your blogger dashboard Open Settings > Search Preferences > Crawlers and indexing > Custom robots.txt > Edit > Yes Here you can make changes in the robots.txt file After making changes, click Save Changes button
View the Existing Custom Robots.txt File
In order to view the existing custom robots.txt for your blog, go the to following URL: http://www.yourblog.blogspot.com/robots.txt Needless to say, please replace yourblog with the name of your blog.
Explanation of Custom Robots.txt File
There are several simple directives in Custom Robots.txt file. Here is the basic explanation of these directives so that you can make informed changes in your file.
Wildcards
Following wildcard characters are often used in robots.txt files.
- means all, everything / means root directory
User-agent
This directive indicates the web crawlers to which the settings in robots.txt will apply.
Disallow
It directs the web crawlers not to crawl the indicated directory or file. For example Disallow: / would tell web crawler not to crawl anything in your blog (because you’re disallowing the root directory). Disallow: /dir/* would direct web crawler not to crawl any file under /dir/ directory. Disallow: /dir/myfile.htm would direct web crawler not to crawl myfile.htm under dir folder. Crawler will crawl all other files under dir directory.
Allow
This directive specifically asks a web crawler to crawl a particular directory or file. For example: Disallow: /dir/myfile.htm Allow: /dir/myfile.htm The overall meaning of the above two lines is that the crawler should crawl /dir/myfile.htm The first line bars the crawler but the second line again allows the crawler to crawl.
Sitemap
Sitemap is a very important file in your website/blog. This file contains the structure of your website. It helps web crawlers to find their way through your blog. The Sitemap: directive tells the crawler the location of your sitemap file. In case of Blogger/Blogspot — you can leave this line as it is. This is it! Should you have any questions regarding custom robots.txt file for Blogger/Blogspot, do let me know in the comments section. I will try my best to assist you. Thank you for connecting with TechWelkin!